Clothing Reviews NLP & Text Classification
This project analyzes more than twenty-three thousand women's clothing reviews to study sentiment, language patterns, and text-driven prediction. The notebook combines exploratory text analysis, VADER sentiment scoring, part-of-speech analysis, and TF-IDF-based machine learning pipelines.
The main analytical payoff is that customer sentiment is overwhelmingly positive, while the most consistent negative feedback centers on sizing and fit. Review text contains enough signal to predict recommendation behavior strongly, but department-level classification is more uneven and reveals where category language overlaps.
Technologies Used
Project Focus
The dataset includes customer age, review title, review text, rating, recommendation flag, feedback count, department, and class labels. The analysis asks two practical questions: what language patterns define the review corpus, and how accurately can review text predict customer recommendation or product department?
To answer that, the notebook moves through cleaning, lemmatization, sentiment scoring, word-distribution analysis, and supervised text classification using TF-IDF features with Random Forest, Naive Bayes, and Logistic Regression.
Dataset Snapshot
The original file contains 23,486 reviews across eight columns. After dropping duplicate review text and handling missingness, the modeling dataset remains large enough to support both descriptive NLP work and supervised text classification.
Best holdout performance in the recommendation prediction task.
Recommendation prediction performs strongly when review text is vectorized with TF-IDF.
Department labels are partially separable, but some classes overlap heavily in language.
Negative reviews consistently highlight size, fit, returns, and disappointment.
Model Performance Readout
The strongest supervised result in the notebook is recommendation prediction. After TF-IDF vectorization and hyperparameter tuning, the Random Forest pipeline reaches strong recall and F1, while Naive Bayes remains competitive but weaker on negative-class separation.
| Metric | Random Forest |
|---|---|
| Accuracy | 0.866 |
| Precision | 0.867 |
| Recall | 0.988 |
| F1 Score | 0.923 |
max_depth=None,
n_estimators=300, and tfidf__max_features=1000. The main weakness
in the confusion matrix is false positives on non-recommended reviews.
Interpretation
Text signal strong
Review text carries strong recommendation signal, especially for identifying positive or recommended reviews.
Class overlap real
Department classification is useful, but some classes such as Intimate, Jackets, and Trend share language with larger classes and are harder to separate cleanly.
Bias toward majority class
High recall is partly driven by the dataset's strong class imbalance toward recommended reviews, so accuracy alone does not tell the whole story.
Key Insights
Review Text Predicts Recommendation Well
TF-IDF features paired with Random Forest produced strong recommendation performance, which shows that review language contains clear sentiment and satisfaction signals.
Customer Sentiment Is Overwhelmingly Positive
Customer feedback is heavily skewed toward positive sentiment, indicating strong overall satisfaction, but also suggesting potential bias where dissatisfied customers are underrepresented.
Fit & Sizing Is The Main Business Problem
Sizing and fit are the most critical drivers of customer satisfaction, appearing frequently in both positive and negative reviews and directly influencing purchase success and return rates.
Department Labels Are Harder Than Recommendation
Certain product categories exhibit high classification confusion, suggesting overlapping product descriptions and ambiguity in category definitions. Tops and Dresses perform better than categories like Intimate, Jackets, and Trend.
Language Patterns Show What Customers Care About
Customer reviews are highly descriptive and opinion-driven, with frequent nouns tied to products and sizing and heavy adjective use around quality, fit, and appearance.
Review Length Splits Into Two Behaviors
Customers show both brief feedback and more detailed narrative reviews. Longer reviews are likely to contain richer insight for product improvement than short reactions alone.
NLP Workflow
The preprocessing steps include deduplication, missing-value handling, lowercase conversion, punctuation and digit removal, stopword filtering, tokenization, and lemmatization. From there, the notebook layers sentiment scoring with VADER and linguistic structure with part-of-speech tagging.
This creates a strong bridge between descriptive NLP and supervised modeling, because the text is explored before it is turned into vector features.
Business Reading
The strongest operational takeaway is that review text can be used to flag likely satisfaction or dissatisfaction early, which makes the project useful for review triage and product issue monitoring.
The weaker department-level separation suggests that category labels overlap in how customers describe products, while the negative-review patterns point very clearly to fit and sizing as the most actionable product issue. Improving sizing consistency would likely reduce returns and improve customer experience faster than generic category-level changes.
Model Visuals
The strongest visuals from the notebook show both the shape of the review corpus and the way the classification models behave once the text is vectorized.
Review Length Distribution
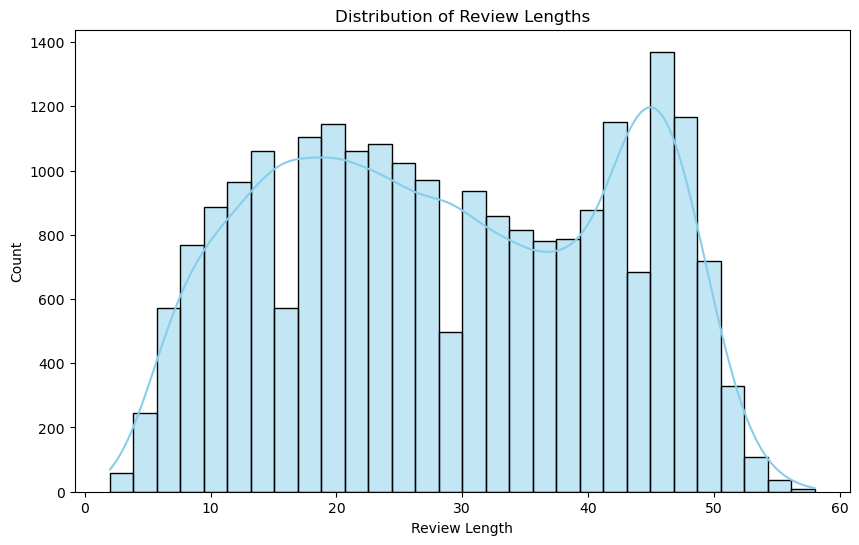
This chart is a nice read on customer behavior. The review corpus shows both short reactions and more detailed writeups, which supports the idea that customers split between quick feedback and fuller product narratives. The longer reviews are likely carrying the richer product-improvement signal.
Positive vs Negative Review Language
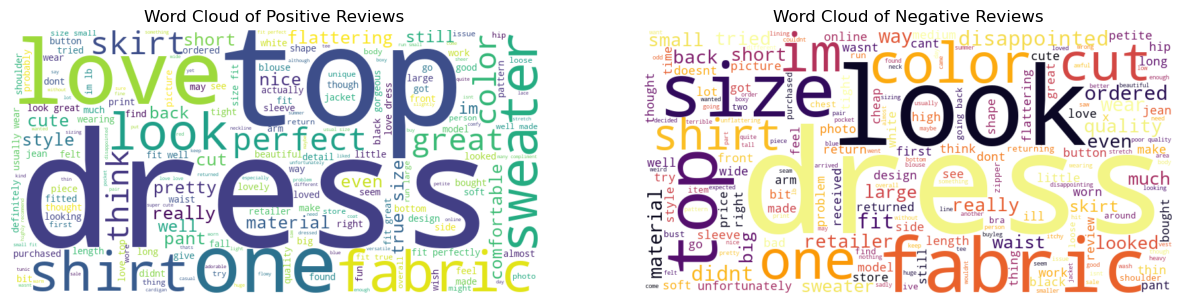
The paired word clouds make the sentiment split tangible. Positive reviews emphasize fit, love, and flattering language, while negative reviews repeatedly surface size, fit, return, cheap, and disappointment-related terms.
Recommendation Confusion Matrix
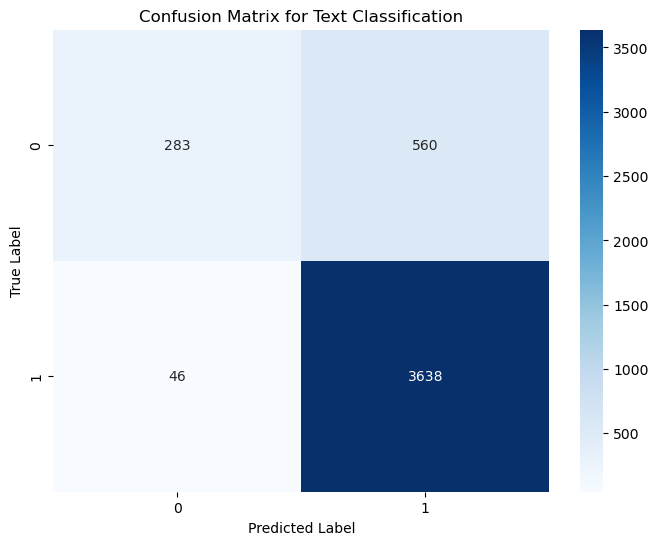
This matrix shows that the recommendation model captures the positive class strongly, but it still misclassifies a meaningful number of non-recommended reviews as recommended. That means the model is much stronger at detecting positive reviews than negative feedback.
Department Classification Confusion Matrix
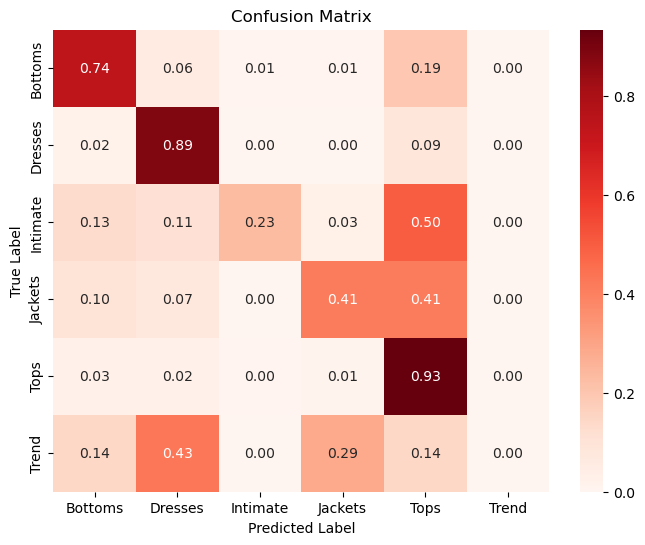
The department matrix makes class overlap easy to see. Dresses and Tops perform much better than smaller categories, while Trend is especially difficult to predict from review language.
Part-of-Speech Distribution
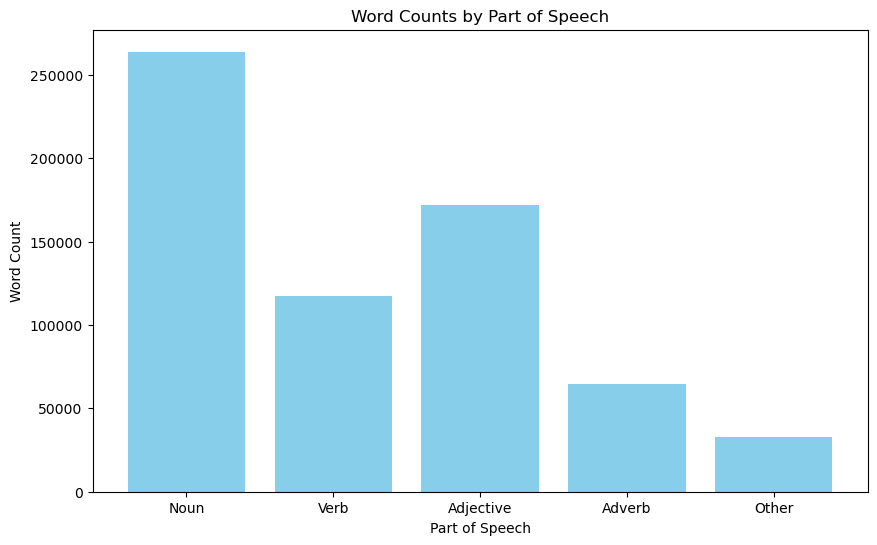
The POS distribution helps explain what the corpus is made of linguistically. The review set is rich in descriptive, opinion-heavy language, which is part of why recommendation classification works as well as it does.
Customer sentiment is overwhelmingly positive, but the smaller negative slice is high-value because it consistently points to sizing and fit problems. The classification models perform strongly on positive-class detection, yet still struggle to catch negative feedback reliably due to class imbalance, which creates risk if the goal is to identify dissatisfied customers quickly.
Business Interpretation
The strongest value in this analysis comes from how consistent the negative feedback is. Positive reviews dominate the dataset, but the smaller negative slice points to a very specific and repeated problem pattern.
Positive Sentiment Dominates The Dataset
Customer sentiment is heavily skewed toward positive reviews, which signals strong overall satisfaction while also biasing both the review pool and the classification task.
Negative Reviews Are Rare But Highly Consistent
Although negative reviews are limited, they repeatedly surface fit, size, return, and disappointment language, which makes them especially actionable for product teams.
Fit And Sizing Drive Experience
Sizing and fit show up across both positive and negative reviews, making them the clearest operational levers for improving satisfaction and reducing returns.
Class Imbalance Limits Negative Detection
The models perform strongly on positive review detection but struggle more with the negative class, which is exactly what the class imbalance in the review distribution would suggest.
Notebook Trace
Cleaning & Preparation
The notebook begins with missingness checks, duplicate review removal, and text cleaning steps including tokenization, stopword removal, and lemmatization.
Sentiment & Language Analysis
VADER polarity scoring, sentiment labels, word clouds, and part-of-speech analysis expose the emotional and structural features of the review text.
Recommendation Classification
TF-IDF features feed Random Forest and Naive Bayes models to predict the recommendation flag, with grid search used to tune the Random Forest pipeline.
Department Classification
A separate logistic regression pipeline predicts department labels from text and reveals which product groups are most linguistically distinct.
Project Highlights
Text Cleaning Pipeline
Cleans review text with tokenization, stopword removal, punctuation filtering, and lemmatization before any sentiment or model work begins.
Sentiment Exploration
Uses VADER polarity scoring, sentiment labels, and word clouds to measure how positive and negative review language differs across the corpus.
TF-IDF Classification
Builds supervised text models for recommendation prediction and department classification using TF-IDF vectorization and multiple scikit-learn estimators.
Model Comparison
Compares Random Forest, Naive Bayes, and Logistic Regression results to show where text signal is strong and where category overlap still limits classification quality.